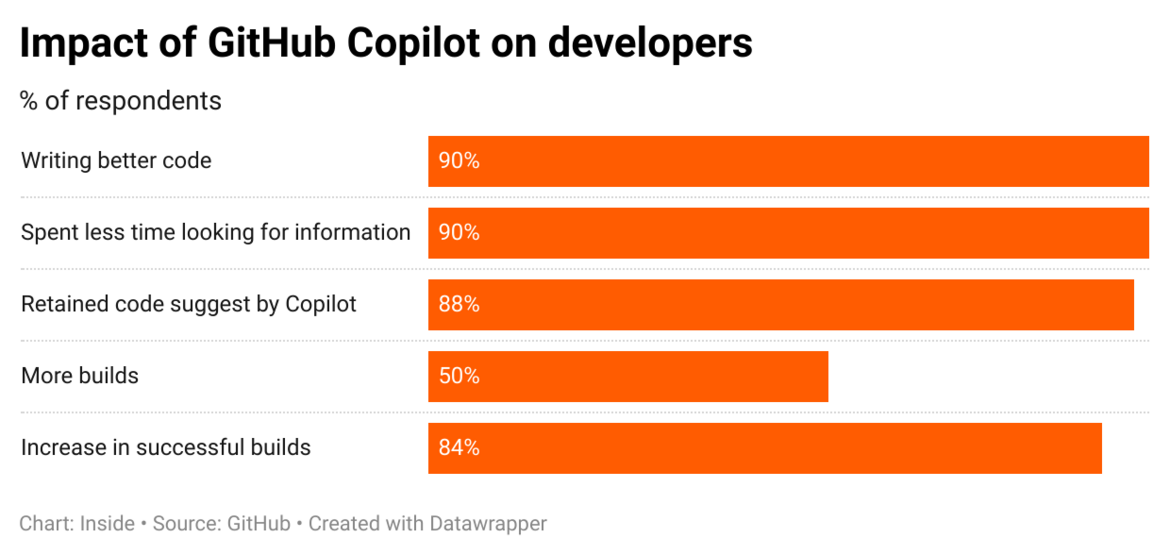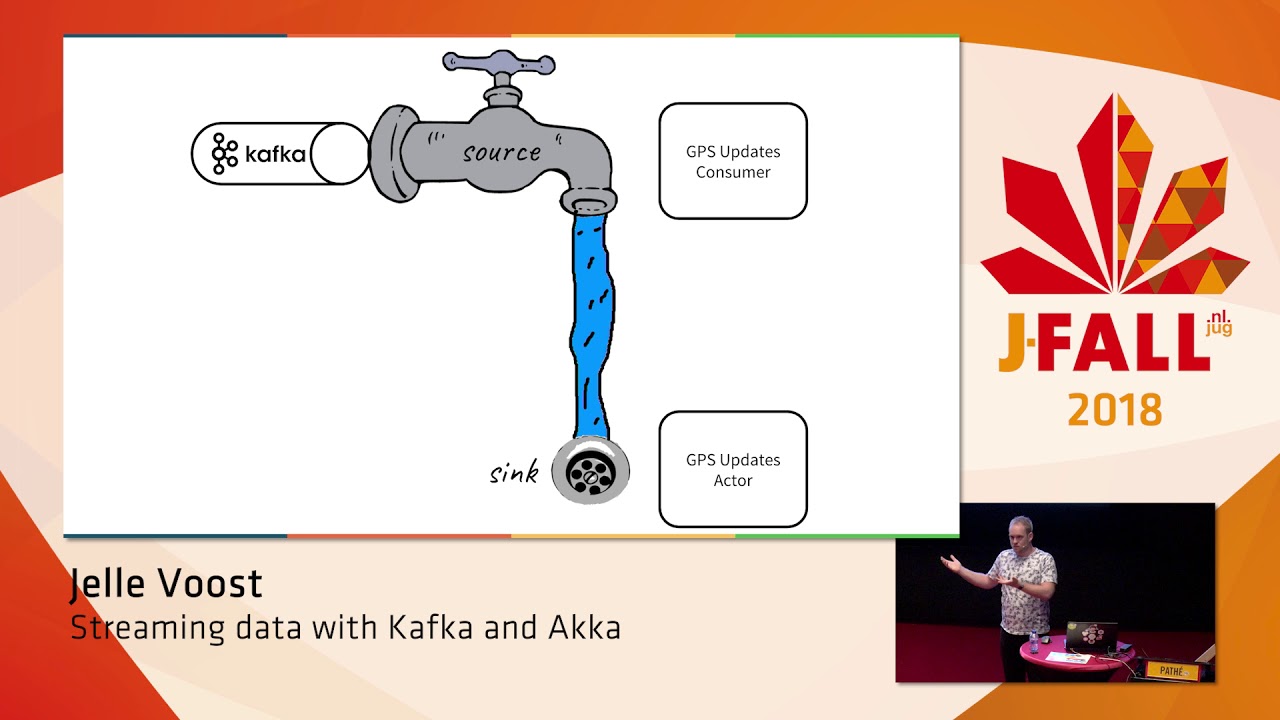




Future Tech is hét jaarlijkse kennis-event voor Microsoft developers in Nederland. Op 17 April as. vindt alweer de vijfde editie plaats in de Jaarbeurs te Utrecht.
Hands-on workshops, keynotes, technical sessions en verschillende Masterclasses aan de hand van topics als AI, Cloud, Devops, Mixed reality en Security.
Future Tech is de Conferentie vóór en dóór Developers, Architects en IT professionals die werken met Microsoft technologieën [ C #, .NET framework, Azure en web technologieën en met internationale TOP sprekers
als James Montemagno (Principal Lead Program Manager voor de .Net community bij Microsoft HQ) en Henry Been (Devops & Azure Architect, Bing Lin (Dataengineer bij ASML), Goran Vuksic (CTO & CO-Founder synthetic AIdata), Yuliya Khadasevich (software Development consultant) en nog vele anderen. Kijk voor voor alle sprekers en of het programma op www.futuretech.nl
Kortom: ben je werkzaam als IT professional binnen het Microsoft ecosysteem ? dan mag je Future Tech 2024 niet missen !
Tickets zijn te koop via www.futuretech.nl